Flat Datacenter Storage Paper Review
March 30, 2016
Distributed System[TOC]
A review for paper Nightingale E B, Elson J, Fan J, et al. Flat datacenter storage[C]//Presented as part of the 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI 12). 2012: 1-15.
Introduction
What is FDS?
- Flat Datacenter Storage (FDS) is a high-performance, fault-tolerant, large-scale, locality-oblivious blob store.
- Using a novel combination of full bisection bandwidth networks, data and metadata striping, and** flow control**, FDS multiplexes an application’s large-scale I/O across the available throughput and latency budget of every disk in a cluster.
How is the Performance?
- 2 GByte/sec per client.
- Recover from lost disk (92 GB) in 6.2 seconds.
- It sets the world-record for disk-to-disk sorting in 2012 for MinuteSort: 1,033 disks and 256 computers (136 tract servers, 120 clients), 1,401 Gbyte in 59.4s.
Architecture
High-level design – a common pattern
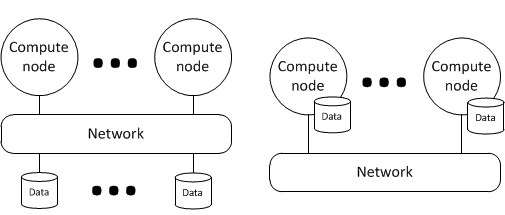
Right distributed model - GFS & HDFS: Data is either on a local disk or a remote disk.
- Move the computation to data. Location awareness adds complexity.
- Why move? Because remote data access is slow.
- Why slow? Because the network is oversubscribed.
Left distributed model – FDS: Object storage assuming no oversubscription. Data is all remote.
- Separates the storage from computation.
- No local vs. remote disk distinction
- simpler work schedulers
- simpler programming models
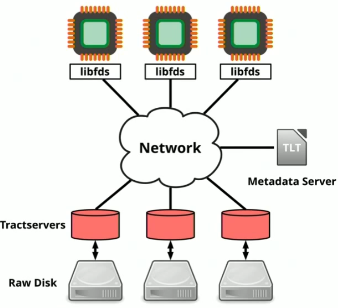
Above it’s the architecture of FDS:
- Lots of clients, and lots of storage servers (“tractservers”)
- Partition the data, and master (“metadata server”) controls partitioning
- Replica groups for reliability
Deisign Overview
How to store data? – Blobs and Tracts
Data is logically stored in blobs.
- A blob is a byte sequence named with a 128-bit GUID.
- Blobs can be any length up to the system’s storage capacity.
- Blobs are divided into tracts.
Tracts are the units responsible for read and write
- Tracts are sized such that random and sequential access achieves nearly the same throughput.
- The tract size is set when the cluster is created based upon cluster hardware.(64kb~8MB)
- All tracts’ metadata is cached in memory, eliminating many disk accesses.
Every disk is managed by a process called a tractserver:
- Services read and write requests from clients.
- Lay out tracts directly to disk by using the raw disk interface.
- Provides API, and the API features are follow:
- Tract reads are not guaranteed to arrive in order of issue. Writes are not guaranteed to be committed in order of issue.
- Tractserver writes are atomic: a write is either committed or failed completely.
- Calls are asynchronous: using callback, allows deep pipelining to achieve good performance.
- Weak consistency to clients
How to organize and manage metadata? – Deterministic data placement
Many systems solve this problem using a metadata server that stores the location of data blocks.
- Advantage: allowing maximum flexibility of data placement and visibility into the system’s state.
- Drawbacks: the metadata server is a central point of failure, usually implemented as a replicated state machine.
FDS uses a metadata server, but it’s role is simple and limited: tract locator table (TLT):
- collect a list of the system’s active tractservers and distribute it to clients.
- With k-way replication, each entry has the address of k tractservers.
- Weighted by disk speed
- Only update when cluster changes
Compute a tract index to read or write, which is designed to both be deterministic and produce uniform disk utilization: Tract_Locator = TLT[(Hash(GUID) + Tract) % len(TLT)]
- Hash(GUID): Randomize blob’s tractserver, even if GUIDs aren’t random (uses SHA-1)
- Tract: adds tract number outside the hash, so large blobs use all TLT entries uniformly
Compute a tract index for Blob metadata, which enable to distribute Blob metadata: Tract_Locator = TLT[(Hash(GUID) - 1) % len(TLT)]
- The metadata server isn’t a single point failure.
- Parallelized operation can be servied in parallel by independent tractservers.
To summarize, FDS metadata scheme has following properties:
- The metadata server is in the critical path only when a client process starts.
- The TLT can be cached long-term, eliminating all traffic to the metadata server under normal conditions.
- TLT contains random permutations of the list of tractservers, which make sequential reads and writes parallel.
What kind of application will /will not benefic from FDS? – Dynamic Work Allocation
- Since storage and compute are no longer colocated, the assignment of work to worker can be done dynamically at fine granularity during task execution, which enables FDS to mitigate stragglers.
- The best practice for FDS applications is to centrally (or, at large scale, hierarchically) give small units of work to each worker as it nears completion of its previous unit.
- Such a scheme is not practical in systems where the assignment of work to workers is fixed in advance by the requirement that data be resident at a particular worker before the job begins.
Replication and Failure Recovery
Replication
- Serialized Blob operation Create, Delete, Extend: client writes to primary, primary executes a two-phase commit with replicas.
- Write to all replicas, read from random replica
- Supports per-blob variable replication
Failure recovery
- each ertry in TLT has a version number to control update, and all operations as well.
- Transient failures: partial failure recovery that complete failure recovery or use other replicas to recover the writes that the returning tractserver missed.
- Cascading tractserver failures: fill more slots in the TLT
- Concurrent tractserver failures: detected as missing TLT entries, and execute normal failure recovery protocol.
- Metadata server failures: using Paxos leader election
Replicated data layout
- The selection of which k disks appear has an important impact on both durability and recovery speed
- A better TLT has O(n^2) entries, so each possible pair of disks appears in anentry of the TLT.
- First, performance during recovery involves every disk in the cluster.
- a triple disk failure within the recovery window has only about a 2/n chance of causing permanent data loss.
- adding more replicas decreases the probability of data loss.
Cluster growth
- Rebalances the assignment of TLT entries so that both existing data and new workloads are uniformly distributed.
- These assignments happen in two phases (
pendingandcommits). - If a new tractserver fails while its TLT entries are pending, increments the TLT entry version and expunges it.
- new tractservers must read from the existing tractserver with a superset of the data required.
Networking
- Network bandwidth = disk bandwidth
- Full bisection bandwidth is stochastic
- Short flows good for ECMP
- TCP hates short flows, but RTS/CTS to mitigate incast
- FDS works great for Blob Storate on CLOS networks.
Reference:
How does FDS (flat datacenter storage) make optimizations around locality unnecessary?