Leveldb: Introduction
November 25, 2016
Database Leveldb[TOC]
看了不少 blog 分析 leveldb,但很少看到有人从设计原因和策略上进行总结。所以这个系列对 leveldb 的实现做一点设计分析,争取将内部实现逻辑串联起来。正如此文中希望探讨的是对于一般的单机数据存储引擎存在哪些问题,Leveldb作为一个经典实现,其解决方案是出于什么考虑,采用什么策略,如何高效实现病解决问题的,做出了哪些权衡以及如何组织代码和工程。
Introduction
Leveldb 库提供持久层 kv 存储,其中 keys 和values 可以是任意字节数组。目前有 C++,golang 的实现。也就是说,Leveldb所处理的每条记录都是一条键值对,由于它基于sequence number提供快照读,准确来说应该是键,序列号,值三元组,由于用户一般关心最新的数据,可以简化为键值对。
作者 Jeff Dean, Sanjay Ghemawat 同时也是设计实现 BigTable 的作者。在 BigTable 中有两个关键部分:master server 和 tablet server。
- master server 负责存储 meta-data,并且调度管理 tablet server;
- tablet server 负责存储具体数据,并且响应读写操作。
Leveldb 可视为 BigTable 中 tablet server 的简化实现。
Features, Limitations, Performance
How to use
详见 leveldb 使用文档
Background
冯诺依曼体系结构的计算机系统主要为两点:存储 + 计算。数据库即为存储方面,依赖于存储硬件特性。
当前磁盘物理结构特性导致 (磁头寻道,旋转延迟):随机读写慢,连续读写快,相差三个数量级。内存和 SSD 同样表现,只不过原因是:连续读写可预判,因此会被优化 (相差量级也没磁盘那么大)。
上述说明:基于目前这样的硬件特性,我们设计存储系统时要尽量避免随机读写,设计为顺序读写。
然而,顺序读和顺序写是相互矛盾的:
- 为了优化读效率,最好是将以有序方式组织数据从而写入相邻的块,以维护顺序读,而这增加了随机写;
- 为了优化写效率,最好是所有的写都是增量写,也就是顺序写,而这增加了随机读。
题外话:常见的优化读操作性能的设计有:二分、hash、B+ 树等。这些方法使用各种查找结构来组织数据,有效提升读操作性能(最少提供了O(logN)),但是增加了随机写操作,大大降低了写操作性能。
因此,如果一个业务对写操作的吞吐量十分敏感,或者写操作数量远远大于读操作,那么应该采取的措施是:优化写操作,也就是尽量将写操作设计为增量写,从而尽可能地减少寻道,以达到磁盘理论写入速度最大值。
这个策略常用于日志或者堆文件这种业务场景中,因为它们是完全顺序的(包括读写),所以可以提供很好的写操作性能。
Leveldb Core Idea
以 LSM(Log Structured Merge) Tree组织数据从而将逻辑场景中的写请求转换为顺序写,利用 write batch 加速写操作,辅以 Bloom Filter 和 Shard LRU cache 等策略优化随机读操作从而保证读效率。
-
关于论文的部分分析详见链接


LSM tree 针对写入速度瓶颈问题而提出的方法,其基本思想是:保存多版本数据,将随机写转换为顺序写,交换读和写的随机 IO。 LSM-Tree的思路是将索引树结构拆成一大一小两颗树,较小的一个常驻内存(MemTable),较大的一个持久化到磁盘(SSTable),他们共同维护一个有序的key空间。
首先数据更新增量写入 MemTable,达到设定阈值大小后保存为有序文件 SSTable 到磁盘中(read only),每个文件保存一段时间内的数据更新。随着数据的不断写入 SSTable 会不断膨胀,为了均衡读写效率,SSTable 文件是一种分层次(level)管理,LevelDB将磁盘中的数据又拆分成多层,每一层的数据达到一定容量后会触发向下一层的归并操作,每一层的数据量比其上一层成倍增长。
LSM tree 主要组成结构为:MemTable(内存数据组织结构)+ SSTable (Sorted String Table,磁盘数据组织结构)+log(保证可恢复未持久化的数据)。
LSM Tree 的主要措施有:
- 对更新进行批量 & 延时处理 (超过大小阈值后将内存中的数据 dump 到磁盘中):减少寻道,提高写操作性能;
- 周期性地利用归并排序对磁盘文件执行合并操作 (compaction):移除已删除和冗余数据,减少文件个数,保证读操作性能。
Leveldb的工程优化
-
Leveldb 采用 write batch 来优化并发写。
对每一个写操作,先通过传入的键值对构造一个 WriteBatch 对象,里面其实就是一个字符串。多个并发写的 write batch 最后会被合并成一个,再写入 log 和 memtable。
-
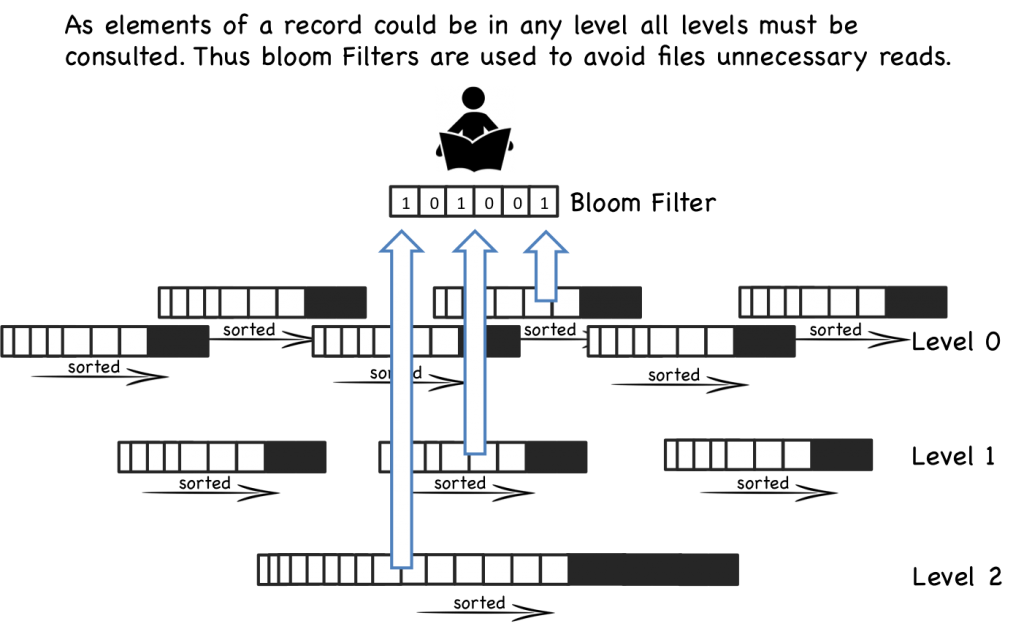
由于 LSM Tree 会产生大量文件,因此 LevelDb 利用 bloomfilter 来避免大量的读操作。
bloomfilter 以概率性算法高效检索一个 key 是否在一个 SSTable (核心为 hash,若判断为不存在则必定不存在,若判断为存在则可能不存在)。
-
Leveldb 是基于磁盘存储的,因此cache优化是非常自然的想法,主要作用还是在加速读操作。
leveldb 中的 cache 分为 Table Cache 和 Block Cache 两种,其中 Table Cache 中缓存的是 sstable 的索引数据,Block Cache 缓存的是 sstable 的 Block 数据(可选打开)。
由于 levelDB 为多线程,每个线程访问 cache 时都会对 cache 加锁。为了保证多线程安全并且减少锁开销,leveldb 定义了一个 SharedLRUCache。
ShardedLRUCache 内部有 16 个 LRUCache,查找 Key 时根据 key 的高四位进行 hash 索引,然后在相应的 LRUCache 中进行查找或更新。当 LRUCache 使用率大于总容量后, 根据 LRU 淘汰 key.
Overall Architecture
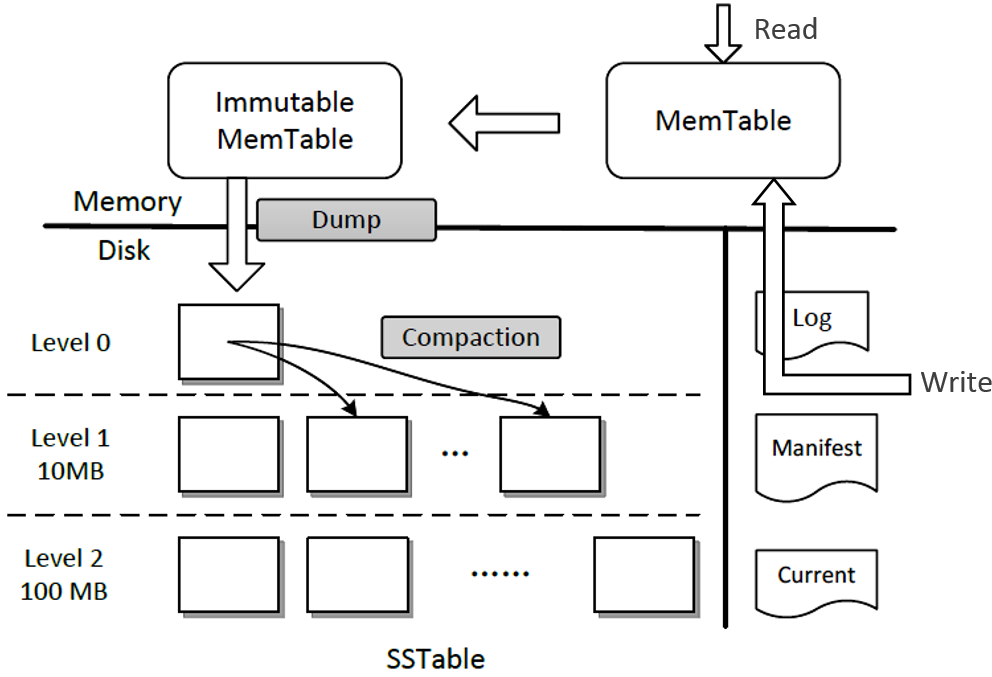
Leveldb 存储主要分为 SSTable 和 MemTable。前者为不可变且存储于持久设备上,后者位于内存上并且可变。其中有两个 MemTable,一个为当前写入 MemTable,另一个为等待持久化的 Immutable MemTable。此外还有一些辅助文件(当前数据库的元数据信息,存放在内存中),后面详述。
Write Operation:当用户需要插入一条 kv 到 Leveldb 中时,首先会被存储到 log 中 (Write Ahead Log, WAL, 保证数据持久性);然后插入到 MemTable 中;当 MemTable 达到一定大小后会转化为 read-only Immutable MemTable,并且创建一个新的 MemTable;同时开启一个新的后台线程将 Immutable MemTable 的内容 dump 到磁盘中,创建一个新的 SSTable。
Deletion Operation:在 Leveldb 中视为特殊的 Write operation,写入一个 deletion marker。
Read Operation:当 leveldb 收到一个 Get 请求时,首先会在 MemTable 进行查找 key;然后在 Immutable MemTable 查找;最后在 SSTable 中查找(从 level 0 到 higher level),直到匹配到一个 kv item 或者为 NULL。确定一个随机的 key 的位置而需要搜索文件的次数的上界是由最大的层数来决定的。
Compaction:每一层所有文件的大小是有限制的,大约是以10倍依次递增。当某一层的总大小超过了它的限制时,合并线程就会从该层选择一个文件将其和下一层的所有重叠的文件进行归并排序产生一个新的 SSTable 文件放在下一层中。合并线程会一直运行下去直到所有层的大小都在规定的限制内。当然,在合并的过程中,LevelDB 会保持除 level 0 之外的每一层上的所有文件的 key 的范围不会重叠,L0 层上文件的 key 的范围是可以重复的,因为它是直接从 memtable 上刷新过来的。
Problem
http://idning.github.io/leveldb-rocksdb-on-large-value.html
问题:
写放大:LevelDB 中的写放大是很严重的。假如,每一层的大小是上一层的10倍,那么当把 i-1 层中的一个文件合并到 i 层中时,LevelDB 需要读取 i 层中的文件的数量多达10个,排序后再将他们写回到 i 层中去。所以这个时候的写放大是10。对于一个很大的数据集,生成一个新的 table 文件可能会导致 L0-L6 中相邻层之间发生合并操作,这个时候的写放大就是50(L1-L6中每一层是10)。
读放大:LevelDB 中的读放大也是一个主要的问题。读放大主要来源于两方面:
- 查找一个 key-value 对时,LevelDB 可能需要在多个层中去查找。在最坏的情况下,LevelDB 在 L0 中需要查找8个文件,在 L1-L6 每层中需要查找1个文件,累计就需要查找14个文件。
- 在一个 SSTable 文件中查找一个 key-value 对时,LevelDB 需要读取该文件的多个元数据块。所以实际读取的数据量应该是:index block + bloom-filter blocks + data block。例如,当查找 1KB 的 key-value 对时,LevelDB 需要读取 16KB 的 index block,4KB的 bloom-filter block 和 4KB 的 data block,总共要读取 24 KB 的数据。在最差的情况下需要读取 14 个 SSTable 文件,所以这个时候的写放大就是 24*14=336。较小的 key-value 对会带来更高的读放大。
解决方法
每个mmtable太小(2M), 存在如下问题:如果写入200G数据, 在db目录下就会有20w个文件, 需要频繁打开/关闭文件, 一个目录里面20w个文件的性能会很差(当然btrfs之类好些);对于50K的value, 一个文件只能放40个key-value对, 效率很低
Compaction不可控:不能自定义compaction函数, 如果可以自定义, 则可以在compaction的时候做ttl功能;compaction不能限速
File Layout
详见 leveldb 实现文档
Source Code Structure
leveldb的实现大致上可以分成以下几层结构:
- 向用户提供的DB类接口及其实现,主要是DB、DbImpl、iter等
- 中间概念层的memtable、table、version以及其辅助类,比如对应的iter、builder、VersionEdit等
- 更底层的偏向实际的读写辅助类,比如block、BlockBuilder、WritableFile及其实现等
最后是它定义的一些辅助类和实现的数据结构比如它用来表示数据的最小单元Slice、操作状态类Status、memtable中用到的SkipList等
leveldb-1.4.0
| +— port <=== 提供各个平台的基本接口 | +— util <=== 提供一些通用工具类 | +— helpers | | | +— memenv <=== Env 的一个具体实现(Env 是 leveldb 封装的运行环境) | +— table <=== sstable 相关的数据格式定义和操作实现 | +— db <=== 主要逻辑的实现 | +— doc | | | +— table_format.txt <=== 磁盘文件数据结构说明 | | | +— log_format.txt <=== 日志文件(用于宕机恢复未刷盘的数据)数据结构说明 | | | +— impl.html <=== 一些实现 | | | +— index.html <=== 使用说明 | | | +— bench.html <=== 测试数据 | +— include | +— leveldb <=== 所有头文件