Leveldb: Storage SSTable
February 15, 2017
Database Leveldb[TOC]
Overall Architecture
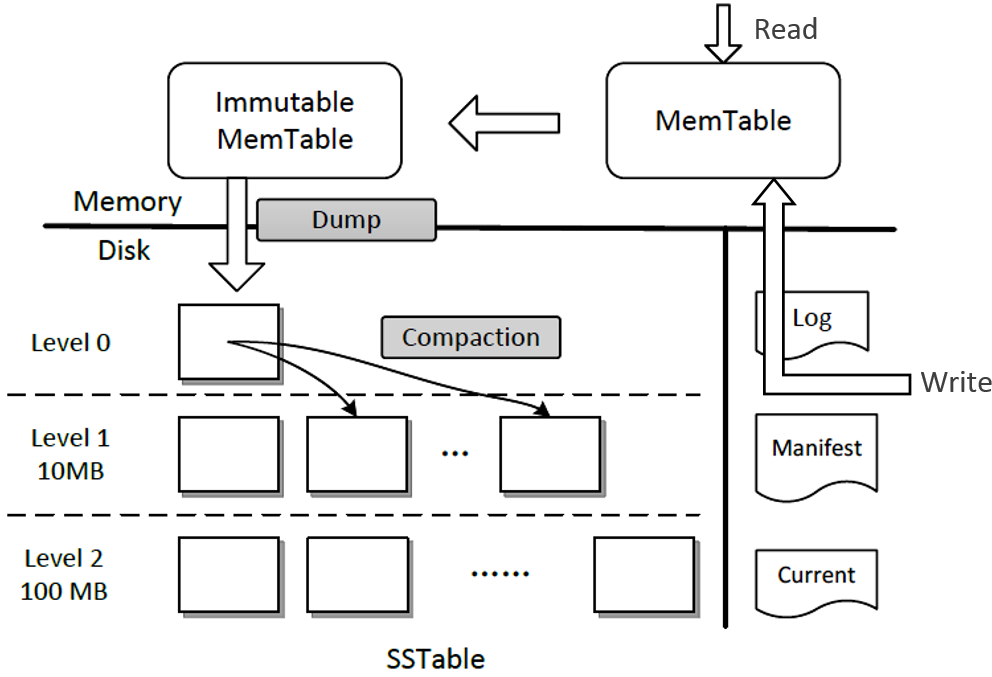
Leveldb 存储主要分为 SSTable(磁盘) 和 MemTable(内存,包括 MemTable 和 Immutable MemTable),此外还有一些辅助文件(数据库元数据信息):Manifest, Log, Current。
本篇主要分析 SSTable:SSTable 文件是持久化在磁盘上的文件,leveldb 存储路径中的 .sst 类型的文件都是 SSTable 文件。本文介绍 Leveldb 的记录在 SSTable 文件中的存储格式是什么,多条记录在单文件中是如何被管理的,多文件又是如何被管理的。
SSTable
sstable 全名 sort-string table,sstable 中的数据都是有序的。除了日志之外, leveldb 的数据统统存储在 sstable 中。
Structure
LevelDB SSTable Layout
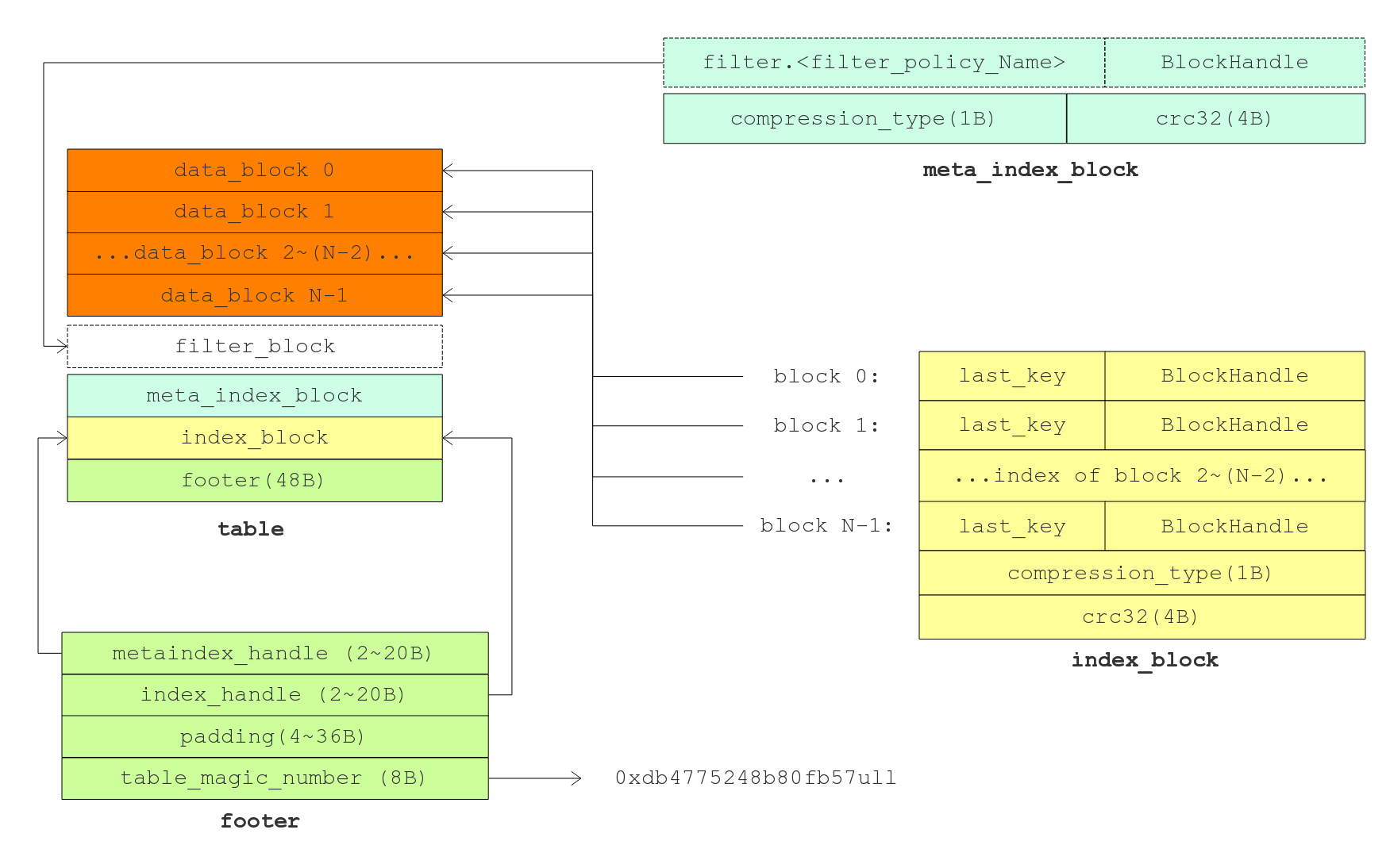
每个 sstable 内部按 block 划分, 布局如上图。然后看看 Table Format 文档关于 table 存储格式,主要包括几个部分:
- data block:直接存储有序键值对的数据块;
- meta block(filter block):存储 key/value 对应的 filter(默认为bloom filter);
- meta index block:对 meta block 的索引。实际上它只有一条记录,key 是 meta index 的名字(也就是 filter 的名字),value 为指向 meta block 起始的位置;
- index block:对 data block 的索引。对于其中的每个记录,其 key >= data block 最后一条记录的 key,同时 < 其后 data block 的第一条记录的key;value是指向 data index 的位置信息;
- footer:置于 table 末尾,固定 48 byte, 包含指向各个分区( data index block 以及 meta index block )的偏移量和大小,读取 table 时从末尾开始读取。
除了 footer block 以外,其余类型 block 的格式都是一致的,主要包含下面几部分。其中 type 指的是采用哪种压缩方式,当前主要是 snappy 压缩。

Footer block
对于leveldb而言,Footer 是线头,从 Footer 开始就可以找到该文件的其他组成部分进而解释整个文件的内容。
metaindex_handle: char[p]; // Block handle for metaindex
index_handle: char[q]; // Block handle for index
padding: char[40-p-q]; // zeroed bytes to make fixed length
// (40==2*BlockHandle::kMaxEncodedLength)
magic: fixed64; // == 0xdb4775248b80fb57 (little-endian
// Block handle 定义如下,包含解释某个 block 的开始和结束位置
class BlockHandle {
private:
uint64_t offset_;
uint64_t size_;
};
// 其中最后的magic number是固定的长度的8字节:
static const uint64_t kTableMagicNumber = 0xdb4775248b80fb57ull;
Data block & Index block
data block layout
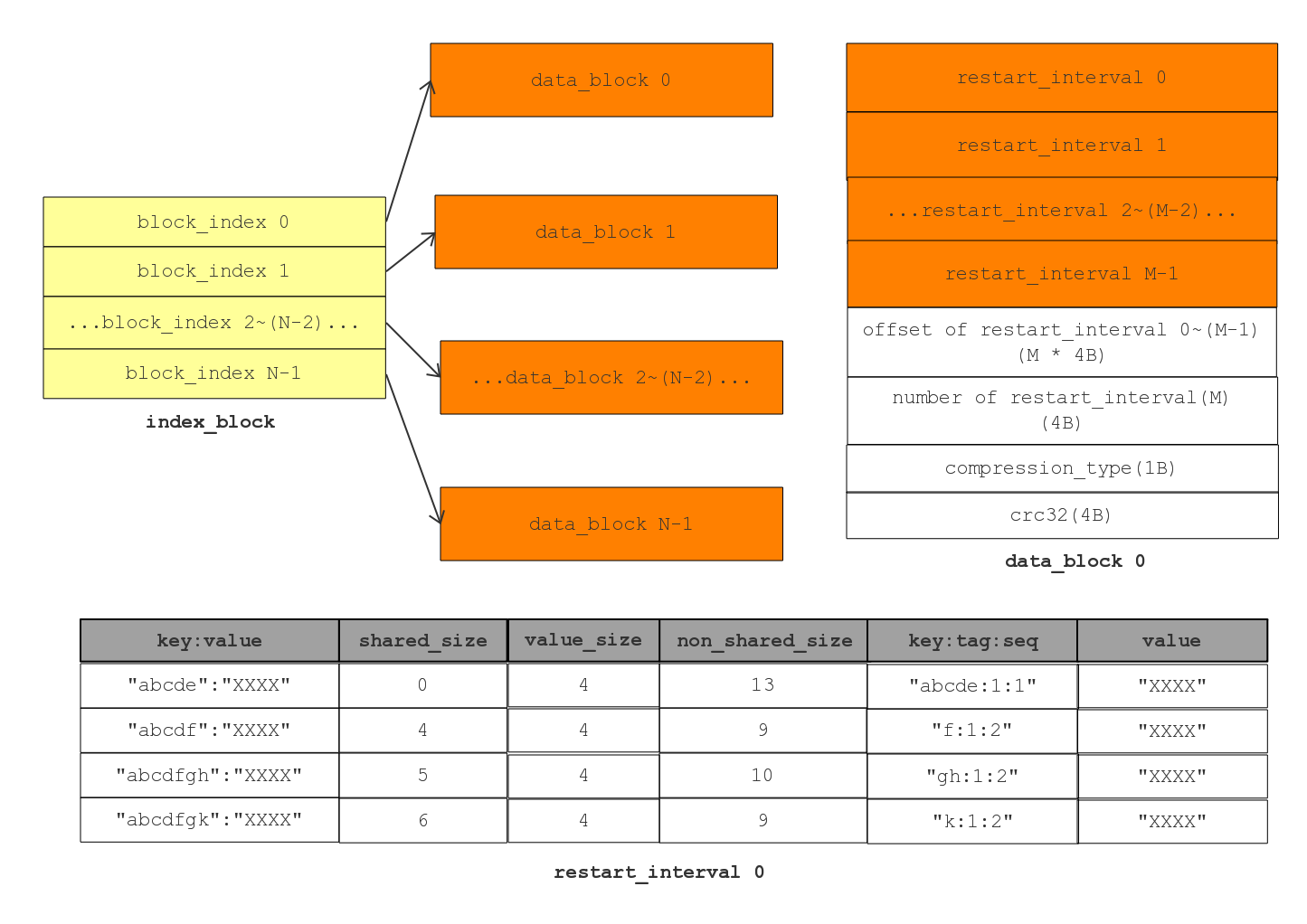
Data Block,存放的就是一系列有序的 key-value,总体来看每个 data block 可分为 key/value 存储区和最后的 restart point 存储区两部分。其中为了节省存储空间和提升查询效率,Data block做了一些改进。
- 当缓存的数据达到一定大小(options.block_size,默认为4KB)之后, 就会 flush 成了一个 block。
- 在一个 block 中,很多key可能有重复的字节,比如“hellokitty”和”helloworld“是两个相邻的key。由于key中有公共的部分“hello”,如果将公共的部分提取可以有效的节省存储空间。出于这种考虑,Leveldb 利用了前缀压缩(prefix-compressed),由于Leveldb 中 key 是按序排列的,这可以显著的减少空间占用。
- 另外,每间隔16个keys (options_->block_restart_interval,默认为16),Leveldb 就取消使用前缀压缩,而是存储整个key (即为 restart point)。最后将这些 restart point 在整个 table 的 offset 记录下来,放在 data block 最后面,可以称为 restart block(所谓 data block 的 flush 就是将所有的 restart point 指针记录下来,并且记录restart point 的个数)。 利用 restart block 可以二分查找指定的 key,极大提升查询效率。
注意,一个SSTable中存在着多个data block,尽管他们之间是有序的,可是你查找的key到底位于哪个block上?典型的sstable文件大小为2M,可以设置的更大,每个sstable 文件中data block 的个数可能上百,如何在这上百个data block中寻找你要的key?显然依次查找效率太低,这时候 index block就起到作用了。
Index Block,组织形式和 data block 基本相同,不同点的地方在于存储的内容。data block存放的客户输入的key/value,而 index block 存放的是索引。
首先 index block 中存放的记录,每个记录是根据前 data block的 last key + 后 block 的 first key 计算出来一个 key comparator(作为两个data block之间的分割线),再结合上一个 data block 的偏移量及大小 (offset , size),作为一组 key-value 存入 index block。也就是说,生成和插入时机是当 data block 插入第一个 key/value 时即需要计算 key comparator 并存入 index block。
所谓的 key comparator,作为两个data block之间的分割线可用于快速地定位出我们要找的 key 位于哪个 data block。比 key comparator 小的 key 在上一个data block,比 key comparator 大的 key 在下一个data block。计算方法为:如果
start<limit,就把 start 修改为 start 和 limit 的共同前缀后面第一个不同字符加1。start: helloleveldb 上一个data block的最后一个key limit: helloworld 下一个data block的第一个key 由于 start < limit, 所以调用 FindShortSuccessor(start, limit) 之后,start 变成: hellom (保留前缀,第一个不相同的字符+1) 这里面有一个特例,即上一个data block 的最后一个 key 可能是下一个 data block 第一个的子串: 此时用上一个 data block 的最后一个 key 作为 key comparator其次是何时生成 index block,index block 在 SSTable 构造完成之后才会刷新,所以对于一个 SSTable 而言的话只有一个 index block。注意,最后计算出 Index Block 在 sstable 中的 offset 和 size 会存放在index_block_handle 中,然后将 index_block_handle 记录在 footer 中,由此可从 footer 寻址到 index block。而 index block 存放的是 {“分割key”:data block的位置信息},所以根据 index block 可以找到任何一个 data block 的起止位置。
最后看看进行一个 key 的 query 如何进行。首先读取出 data index block(这个部分可以常驻内存),得到里面的 restart point 部分。针对 restart point 进行二分。因为 restart point 指向的 key 都是全量的 key。如果确定在某两个 restart point 之间之后,就可以遍历这个 restart point 之间范围分析 seperator。得到想要查找的 seperator 之后对应的 value 就是某个 data block offset。读取这个 data block 和之前的方法一样就可以查找 key 了。对于遍历来说,过程是一样的。
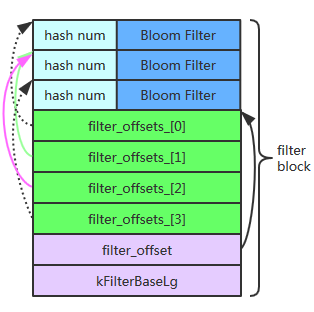
Meta block (filter block) & meta index block
filter block layout
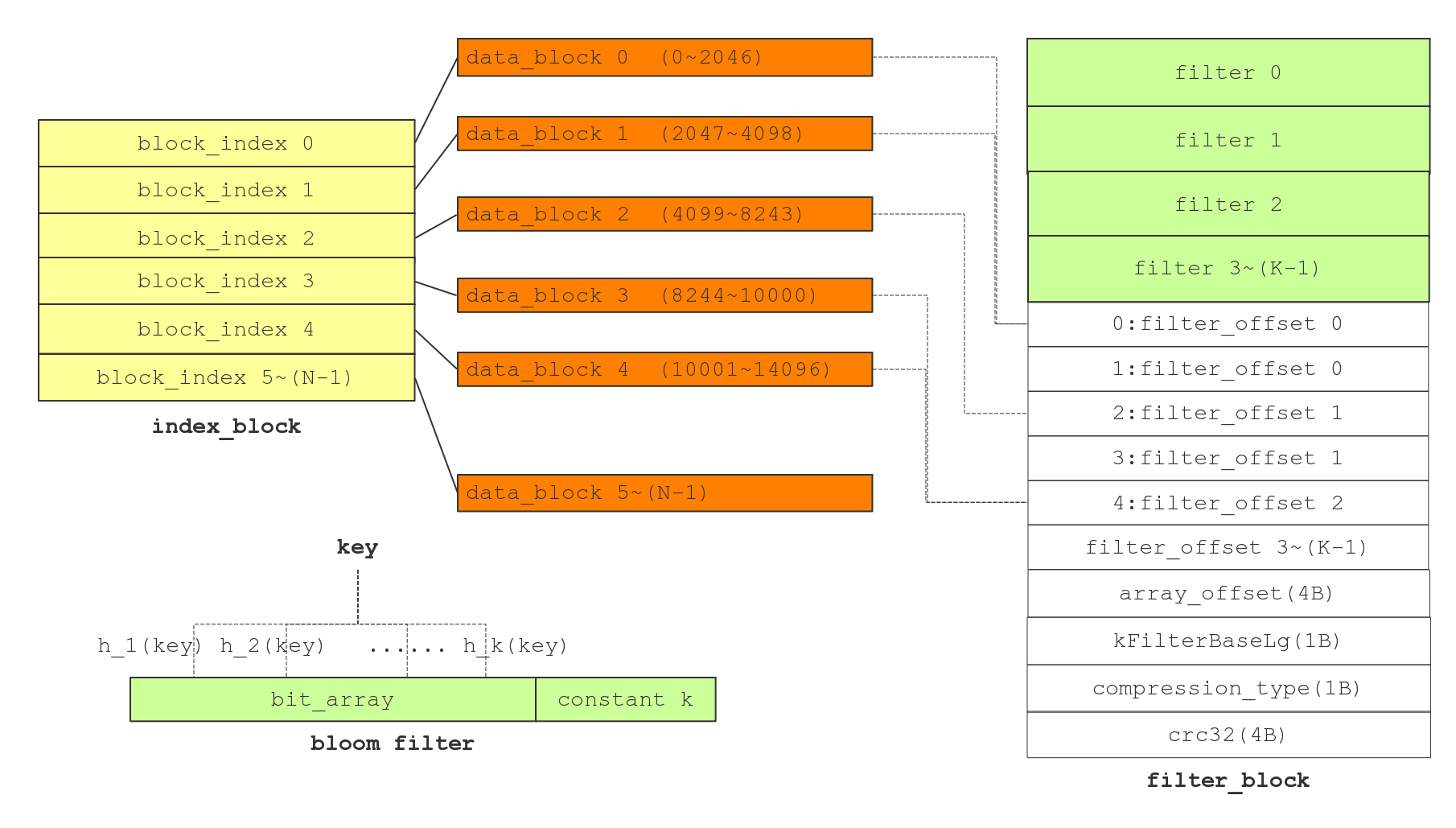
meta block 的作用在于快速确定是否存在某个 key,如果不存在则没必要去遍历 data block 查找该 key 了,从此提升查询效率。利用 Bloom Filter 可以快速判断某个key是否属于某个集合。其原理比较简单,首先定义一个很大的数组作为位图,初始时位图中的每个元素都是0,向集合添加某个key的时候计算一组hash值(多个不同的hash函数)并根据结果将位图对应位置的位设为1,查询某个key是否存在时同样计算一组hash值判断对应位是否为1。
为 bloom filter 选择合适大小的位图是平衡 efficiency 和 false positive 的关键,更多参考 bloom filter wiki。核心公式是:k = m /n * ln2(k 为哈希函数个数,m 为位图 bit 数量,n 为 key 个数)。
class BloomFilterPolicy : public FilterPolicy
{
private:
size_t bits_per_key_; // 一个key占多少位
size_t k_; // 哈希函数个数
public:
// 严格意义上讲,Leveldb Bloom Filter创建时只有一个参数即bits_per_key
// bits_per_key = m/n,位图bit数除以key的个数,bits_per_key越大越好
explicit BloomFilterPolicy(int bits_per_key): bits_per_key_(bits_per_key)
{
// We intentionally round down to reduce probing cost a little bit
k_ = static_cast<size_t>(bits_per_key * 0.69); // 0.69 =~ ln(2)
if (k_ < 1) k_ = 1;
if (k_ > 30) k_ = 30;
}
……
};
由核心公式可以看到,为了尽可能的降低虚概率,最优的hash函数个数可能很高,比如需要10个hash函数,这势必带来很多的计算,而且要设计多个不同的hash函数。论文 Less Hashing, Same Performance: Building a Better Bloom Filter 提供了一个思想,通过对一个1个 hash 函数进行多次移位和加法,以达到多个hash 的结果。
for (size_t i = 0; i < n; i++) // 外层循环是每一个key值
{
// Use double-hashing to generate a sequence of hash values.
// See analysis in [Kirsch,Mitzenmacher 2006].
uint32_t h = BloomHash(keys[i]);
const uint32_t delta = (h >> 17) | (h << 15); // Rotate right 17 bits
// 使用k个哈希函数,计算出k位,每位都赋值为1。
// 为了减少哈希冲突,减少误判。
for (size_t j = 0; j < k_; j++)
{
// 得到元素在位列bits中的位置
const uint32_t bitpos = h % bits;
/*
bitpos/8计算元素在第几个字节;
(1 << (bitpos % 8))计算元素在字节的第几位;
例如:
bitpos的值为3, 则元素在第一个字节的第三位上,那么这位上应该赋值为1。
bitpos的值为11,则元素在第二个字节的第三位上,那么这位上应该赋值为1。
为什么要用|=运算,因为字节位上的值可能为1,那么新值赋值,还需要保留原来的值。
*/
array[bitpos/8] |= (1 << (bitpos % 8));
h += delta;
}
}
接下来就是 mata block(filter block)如何组织各个 filter。由于无法预知客户到底存放多少 key,因此 n 不能确定范围,由此导致位图的大小 m 也很难事先确定,所以 leveldb 设计个全局的 Bloom Filter 并不实际。如果设置的 m 过大则浪费内存,如果设置的 m 过小则造成过大 false positive。
leveldb 的做法是每隔一定大小的存储数据(如上图所示,实际上就是每个data block)就生成一个 bloom filter,多个 bloom filter 协同完成任务,因此平衡内存使用和false positive。由此产生两个问题:
何时发起计算一个 filter 位图:当缓存的 kv 数据达到一定大小(
options.block_size,默认为4KB)之后, 就会 flush 成了一个 block,此时会触发 filter 位图计算。void FilterBlockBuilder::StartBlock(uint64_t block_offset) { uint64_t filter_index = (block_offset / kFilterBase); // 本意是超过2kb就计算位图,但发起时机不受其控制 assert(filter_index >= filter_offsets_.size()); while (filter_index > filter_offsets_.size()) { // 可能造成多轮的GenerateFilter函数调用,除了第一轮产生位图外其余轮次皆轮空 GenerateFilter(); } }怎么区分不同轮次 filter 位图之间的边界:leveldb 利用 vector (
filter_offsets_) 记录下每一轮位图截止位置,用于分割位图(result_)防止位图的边界混淆,然后将下一轮 keys 计算得来的位图继续追加到result_字符串。void FilterBlockBuilder::GenerateFilter() { const size_t num_keys = start_.size(); if (num_keys == 0) { // Fast path if there are no keys for this filter filter_offsets_.push_back(result_.size()); return; } // Make list of keys from flattened key structure …… // Generate filter for current set of keys and append to result_. /*先记录下上一轮位图截止位置,防止位图的边界混淆*/ filter_offsets_.push_back(result_.size()); /*将本轮keys计算得来的位图追加到result_字符串*/ policy_->CreateFilter(&tmp_keys_[0], static_cast<int>(num_keys), &result_); …… }
最后是 meta index block,其格式和 idex block 一样,但只有一个 key/value,其中 key = filter.leveldb.BuiltinBloomFilter2, 而 value = meta block 起始位置,以此定位所有 filter。
Main Operation (todo)
SSTable的写入
首先,我们考虑在内存中构建一个连续的内存区域代表一个block的内容,它又可以分为两部分:1. 数据的写入 2. 数据写入完毕后附加信息的添加。 先考虑追加一条记录,我们需要知道哪些东西?
- 当前block提供给数据的剩余空间以确定是否需要换block
- 当前的重启点以确定共享前缀
- 当前重启点已有的key数量以确定是否将本次写入作为新的重启点
- 确保key的有序性,所以必须知道上次添加的key
在确定这些需要的信息后,追加的过程就是查找和维护这些信息以及单纯的memcpy了。
第二步,让我们考虑在数据写入完毕之后需要为block添加其他信息的过程:
- 我们需要记录所有的重启点和重启点位置,我们不得不在追加的时候来维护它们,看来得回去改上面的代码了
- 我们得从配置元数据中得到压缩类型
- 最后我们得记录CRC
现在,我们可以把这么一段char[]的数据转换成Slice表达的block了。接下来,让我们考虑如何批量的把数据写入单个SSTable文件中。这同样分为三个步骤:1. 追加数据 2. 附加信息 3. Flush到文件。 我们依次考虑。
追加数据需要做哪些:
- 知道当前block及当前block能否再添加一条数据
- 维护有序性,需要上一次的key和新加key比较
- 如果生成新的block,为了维护索引,需要为将被替换的block生成索引记录,所以必须维护一个index Block
- 维护过滤器信息(这一部分将在布隆过滤再详细解释,可以暂时忽略)
- 为了决定是否需要刷到文件中去,需要知道已写的block数
实际上向文件写入是以Block为单位的,当我们完成一个Block时,在将它写入文件时需要做什么呢?
- 检查工作,确定block确实需要写入
- 压缩工作
- 通知工作,告知index Block和Filter Block的维护方
- 重置工作,将当前block重置,准备下一次追加
最后,当数据全部添加完毕,该SSTable文件从此将不可变更,这一步需要执行的是:
- 写入最后一块data block
- 写入Meta Block
- 根据上文写入时留存的位置信息构建Meta Index Block
- 写入Meta Index Block
- 将最后的data block位置信息写入Index Block中,并将Index Block写入文件
- 写入Footer信息
SSTable的遍历
SSTable的遍历主要委托给一个two level iterator处理,我们只需要弄清楚它的Next操作就能明白其工作原理。所谓的two level,指的是索引一层,数据一层。在拿到一个SSTable文件的时候,我们先解析它的Index block部分,然后根据当前的index初始化data block层的iterator。接下来我们主要关注Next的过程。
分为两种情形:
- 当前记录不是当前Data Block的最后一条,只需要data iter向前进一步即可
- 当前记录是最后一条,这时就要先前进一步index iter,得到data block的位置信息
- 读取data block,此处先暂时省略table cache的优化,简单起见都是从文件中读
- 创建新的data iter
当然,二级迭代器还做了许多的其他工作,比如允许你传入block function,但这和我们讨论的主线无关,这里就不过多陈述了。
SSTable的查询
SSTable的查询也委托给iter处理,其主要过程就是对key的定位,也是主要分为三部分:
- 定位到哪个block
- 迁移到该block上
- 定位到block中的哪一条
无论是index block还是data block,它们的iter实现是一致的,其查找都遵循以下过程:
- 通过重启点进行二分查找
- 跳到最大的不比目标大的重启点,遍历查找,一直到一个不比目标小的key出现
这里最绝妙的是两点
- index block的设计和二级迭代器,一方面通过这种手段进行快速定位,另一方面将遍历和查找统一到一个框架下,不可谓不妙
- 重启点的设计,避免解析数据内容快速使用二分查找定位key的大致区域
我们都知道磁盘的读写是十分耗时的,索引的手段大量减少了磁盘读的必要。当然,还有许多加速的手段比如过滤器和缓存,我们将在最后一节详细解释。
Component (todo)
SSTable 在代码上主要由以下两部分组成:
- 读相关: Table、Block 和对应的 Iterator 实现
- 写相关:BlockBuilder 和 TableBuilder
可以看出来这也是个典型的二层委托结构了,上面的层次将操作委托给下面层次的类执行,自己管控住progress的信息,控制当前的下层实体。这里我们主要关心Table和Block中应该存放哪些信息以支持它们的操作。
TableBuilder类声明(include/leveldb/table_builder.h, table/table_builder.cc)
class LEVELDB_EXPORT TableBuilder {
public:
// Create a builder that will store the contents of the table it is
// building in *file. Does not close the file. It is up to the
// caller to close the file after calling Finish().
TableBuilder(const Options& options, WritableFile* file);
TableBuilder(const TableBuilder&) = delete;
void operator=(const TableBuilder&) = delete;
// REQUIRES: Either Finish() or Abandon() has been called.
~TableBuilder();
// Change the options used by this builder. Note: only some of the
// option fields can be changed after construction. If a field is
// not allowed to change dynamically and its value in the structure
// passed to the constructor is different from its value in the
// structure passed to this method, this method will return an error
// without changing any fields.
Status ChangeOptions(const Options& options);
// Add key,value to the table being constructed.
// REQUIRES: key is after any previously added key according to comparator.
// REQUIRES: Finish(), Abandon() have not been called
void Add(const Slice& key, const Slice& value);
// Advanced operation: flush any buffered key/value pairs to file.
// Can be used to ensure that two adjacent entries never live in
// the same data block. Most clients should not need to use this method.
// REQUIRES: Finish(), Abandon() have not been called
void Flush();
// Return non-ok iff some error has been detected.
Status status() const;
// Finish building the table. Stops using the file passed to the
// constructor after this function returns.
// REQUIRES: Finish(), Abandon() have not been called
Status Finish();
// Indicate that the contents of this builder should be abandoned. Stops
// using the file passed to the constructor after this function returns.
// If the caller is not going to call Finish(), it must call Abandon()
// before destroying this builder.
// REQUIRES: Finish(), Abandon() have not been called
void Abandon();
// Number of calls to Add() so far.
uint64_t NumEntries() const;
// Size of the file generated so far. If invoked after a successful
// Finish() call, returns the size of the final generated file.
uint64_t FileSize() const;
private:
bool ok() const { return status().ok(); }
void WriteBlock(BlockBuilder* block, BlockHandle* handle);
void WriteRawBlock(const Slice& data, CompressionType, BlockHandle* handle);
struct Rep;
Rep* rep_;
};
BlockBuilder 类声明(table/block_builder.h,table/block_builder.cc)
class BlockBuilder {
public:
explicit BlockBuilder(const Options* options);
// Reset the contents as if the BlockBuilder was just constructed.
void Reset();
// REQUIRES: Finish() has not been called since the last call to Reset().
// REQUIRES: key is larger than any previously added key
void Add(const Slice& key, const Slice& value);
// Finish building the block and return a slice that refers to the
// block contents. The returned slice will remain valid for the
// lifetime of this builder or until Reset() is called.
Slice Finish();
// Returns an estimate of the current (uncompressed) size of the block
// we are building.
size_t CurrentSizeEstimate() const;
// Return true iff no entries have been added since the last Reset()
bool empty() const {
return buffer_.empty();
}
private:
const Options* options_;
std::string buffer_; // Destination buffer
std::vector<uint32_t> restarts_; // Restart points
int counter_; // Number of entries emitted since restart
bool finished_; // Has Finish() been called?
std::string last_key_;
// No copying allowed
BlockBuilder(const BlockBuilder&);
void operator=(const BlockBuilder&);
};
FilterBlockBuilder 类声明(table/filter_block.h,table/filter_block.cc)
class FilterBlockBuilder {
public:
explicit FilterBlockBuilder(const FilterPolicy*);
void StartBlock(uint64_t block_offset);
void AddKey(const Slice& key);
Slice Finish();
private:
void GenerateFilter();
const FilterPolicy* policy_;
std::string keys_; // Flattened key contents
std::vector<size_t> start_; // Starting index in keys_ of each key
std::string result_; // Filter data computed so far
std::vector<Slice> tmp_keys_; // policy_->CreateFilter() argument
std::vector<uint32_t> filter_offsets_;
// No copying allowed
FilterBlockBuilder(const FilterBlockBuilder&);
void operator=(const FilterBlockBuilder&);
};
class FilterBlockReader {
public:
// REQUIRES: "contents" and *policy must stay live while *this is live.
FilterBlockReader(const FilterPolicy* policy, const Slice& contents);
bool KeyMayMatch(uint64_t block_offset, const Slice& key);
private:
const FilterPolicy* policy_;
const char* data_; // Pointer to filter data (at block-start)
const char* offset_; // Pointer to beginning of offset array (at block-end)
size_t num_; // Number of entries in offset array
size_t base_lg_; // Encoding parameter (see kFilterBaseLg in .cc file)
};